Prima dell’avvento delle interfacce grafiche, la comunicazione uomo-macchina, locale o remota che fosse, avveniva esclusivamente in modalità a caratteri, o testuale. Nei computer ogni carattere è rappresentato da un codice, e sono proprio questi codici ad essere utilizzati sia per i dati da visualizzare, che per la digitazione dei comandi.
E’ un sistema efficiente, che è utilizzato tutt’oggi soprattutto in ambito professionale per l’accesso a computer remoti. Anche le codifiche si sono però evolute con il tempo e in risposta a necessità specifiche. Si va da quella più antico, il Murray Baudot (dal nome dei due autori, risalente alla fine dell’800) a 5 bit, alla famiglia del moderno Unicode, che può arrivare a 21 bit.
Negli anni ’70 quelli più diffusi erano l’EBCDIC (Extended Binary Coded Decimal Interchange Code) della IBM e l’ASCII (American Standard Code for Information Interchange) definito dall’American National Standards Institute (ANSI). L’EBCDIC dominava in ambito IBM professionale, l’ASCII era sostanzialmente lo standard per il resto del mondo informatico.
La codifica originariamente utilizzava 7 bit. I primi 32 caratteri e il 128′ sono caratteri di controllo, che non sono usati per rappresentare un carattere, ma per identificare una azione. Ad esempio, il codice 8 rappresenta lo spazio all’indietro o il 127 il cancella.
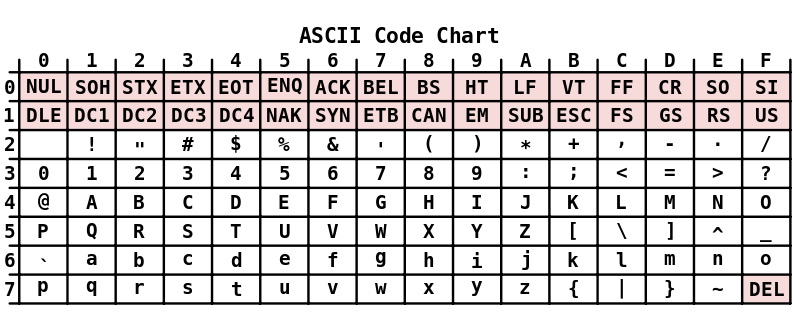
Sono rappresentate tutte le lettere dell’alfabeto anglosassone, maiuscole e minuscole, ma non ci sono vocali accentate. Questo è stato un problema marginale fino a quando si usavano stampanti e le telescriventi, su cui si poteva aggirare la mancanza sovrastampando vocale e accento, ma che si è aggravato sensibilmente nel passaggio alla visualizzazione a video.
La soluzione era quella di estendere la codifica. Peraltro i computer lavoravano su 8 bit, era quindi molto facile raddoppiare il numero di simboli rappresentabili aggiungendo un bit in più alla codifica. Nacquero quindi vari extended ASCII, ad 8 bit, che mantenevano la codifica originaria nella pagina bassa (i primi 128 codici), mappando nuovi caratteri nella pagina alta. Di codifiche ce ne sono varie, identificate con un codice chiamato appunto codepage (CP). L’IBM per il suo 5150, ne propose varie, come la 437 per il Nordamerica, o la 850 per l’Europa centrale. Nella pagina superiore sono rappresentati caratteri specifici per i linguaggi locali, ed un set di blocchi semigrafici originariamente pensati per la creazione di moduli.

A questo punto la questione era chiusa per quanto riguardava i personal computer, in cui la memoria video a caratteri è solitamente mappata: ad ogni posizione (riga, colonna) del video corrispondono una o più celle di memoria, per cui per posizionare una scritta sul video è sufficiente scrivere i codici giusti nelle rispettive celle di memoria. Lo stessa tecnica era utilizzata anche per definire gli attributi di un carattere (come colore, grassetto o sottolineato),
Nelle comunicazioni remote questo ovviamente non è possibile, quindi è necessario inframezzare ai dati veri e propri, dei dati aggiuntivi per indicare il punto su cui iniziare a scrivere e/o gli attributi da utilizzare per il testo. In mancanza di uno standard specifico, ogni produttore di videoterminali ne aveva messo a punto uno proprietario, e spesso capitava di avere incompatibilità anche fra modelli diversi dello stesso produttore.
E’ facile immaginare quanto questa complessità creasse problemi. Nei personal computer era relativamente semplice configurare i programmi che facevano un uso intensivo del posizionamento sullo schermo. Programmi come Calcstar e Wordstar, ad esempio, avevano un programma esterno per configurare sia il monitor che la stampante. Nelle BBS (e nei sistemi aperti), in cui non era nota a priori la tipologia di terminale, la cosa era difficilmente gestibile, visto il numero elevatissimo di opzioni in gioco. Per farsene una idea è sufficiente consultare il database dei terminali dei sistemi *nix.
Per mettere un po’ di ordine in questa babele era necessario definire uno standard. Nel 1979 l’ANSI lo rilasciò con l’identificativo X3.64, sebbene sia più noto come Sequenze di escape ANSI. L’escape è il nome di uno dei codici di controllo ASCII (1b esadecimale, 27 decimale), che viene utilizzato come preambolo per segnalare che i caratteri successivi sono da interpretare come un comando da eseguire, e non come dati da visualizzare. Le sequenze definiscono una serie di comandi che consentono di avere un controllo completo sulla visualizzazione.

Il primo terminale di un grande costruttore ad usare le sequenze ANSI è stato il VT100 della Digital Equipment, un prodotto molto comune a cavallo fra gli anni 70 ed 80, e per questo che le configurazioni per VT100 e terminali ANSI sono sostanzialmente intercambiabili. Questo ha favorito non poco l’affermazione dello standard, che nel giro di pochi anni ha soppiantato le implementazioni proprietarie.
Ovviamente è dovuto passare un po’ di tempo prima di vederne gli effetti sul campo. Limitandoci al nostro ambito, le sequenze ANSI sono state implementate in MsDos nel 1983 con la versione 2.0, che implementava il device driver ANSI.SYS. Il sistema operativo di per se supportava infatti solo le funzionalità minime (BS arretramento, CR a capo, LF linea successiva, BEL campanello).
Agli albori dell’epoca dei BBS le velocità bassissime consentite dai modem disponibili scoraggiavano comunque l’uso di qualsiasi cosa non fosse strettamente necessario alla comunicazione. A 300 o a 1200 baud, l’invio di una sequenza di controllo produceva una marcata pausa nel flusso dei dati sul video.
Grazie al perfezionamento della tecnologia, la disponibilità di velocità di comunicazione progressivamente maggiori ha consentito di avviare un processo di abbellimento della comunicazione, ed ai sysop di personalizzare il proprio BBS con elementi semigrafici, passando dall’ascii art – la grafica costruita utilizzando i caratteri ASCII a 7 bit, all’ansi art – che invece sfrutta sia la codifica estesa ASCII che i le sequenze di escape ANSI per generare immagini che per gli standard i quegli anni erano estramemente d’impatto.
Era ovviamente improbabile che si utilizzassero strumenti professionali come il VT100 (che nel 1980 costava circa 2000$) per accedere ai BBS. La stragrande maggioranza degli utenti usava home o personal computer e programmi di comunicazione <<<LINK>>>.
 Link utili
Link utili- La pagina di Wikipedia sui codici ANSI
- Il manuale VT100 su bitsavers
La foto del VT100 è di Ade Bradshaw con licenza CC BY-NC-SA 2.0